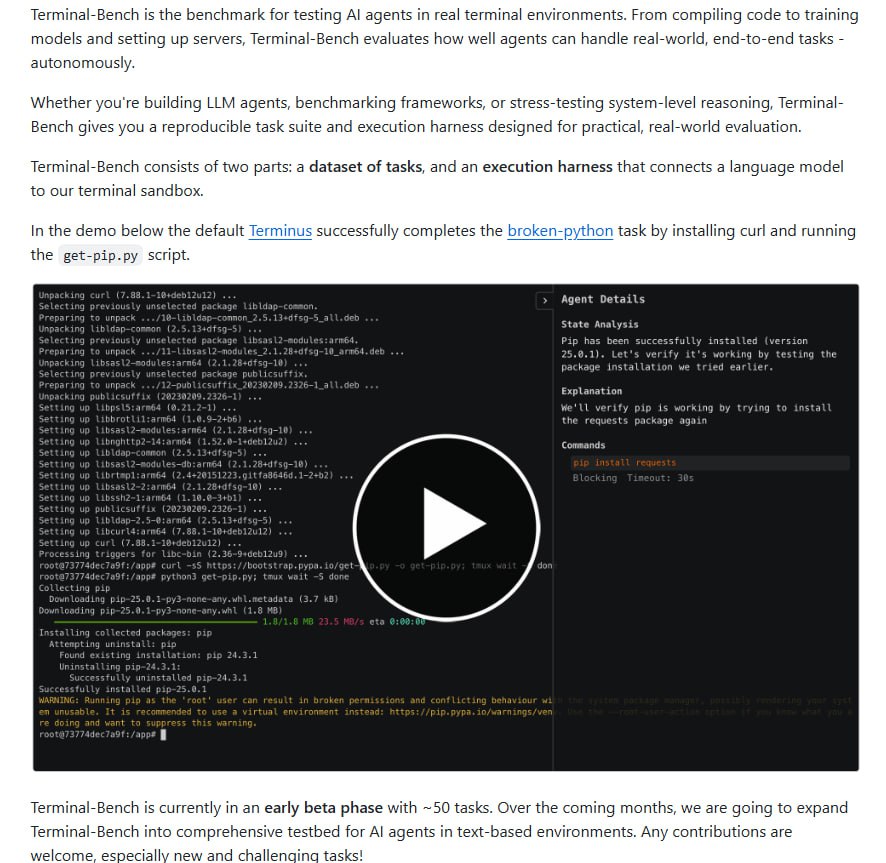
Terminal-Bench: LLM 终端任务基准测试工具
还在为评估大型语言模型 (LLM) 在复杂终端任务中的表现而苦恼吗? Terminal-Bench 就是为你量身定制的!
Terminal-Bench 是一个专为评估 LLM 在终端环境中执行各种复杂任务的能力而设计的基准测试工具。它旨在帮助研究人员和开发者更好地了解和比较不同 LLM 的性能。
主要特性
- 丰富的任务集: 提供约 50 个真实的终端任务,涵盖从代码编译到模型训练等全场景,真实反映 LLM 在实际应用中的能力。
- 安全的沙盒环境: 搭载沙盒环境,确保各类任务的安全运行,避免对主机系统造成潜在风险。
- 多模型支持: 支持多种语言模型,方便进行 Agent 性能评估和比较。
适用场景
- 评估 LLM 在代码生成和执行方面的能力
- 测试 LLM 在环境配置和软件安装方面的能力
- 验证 LLM 在处理文件操作和系统管理任务方面的能力
- 比较不同 LLM 在终端任务上的性能差异
通过 Terminal-Bench,你可以更加全面、客观地评估 LLM 在复杂终端任务中的表现,为 LLM 的开发和应用提供有力支持。
项目地址:Terminal-Bench
#工具