Lightly Train: 无需标签的工业级计算机视觉模型预训练框架
在计算机视觉领域,预训练模型已经成为提高模型性能和加速训练的关键。然而,传统的预训练方法往往依赖于大量标注数据,这在工业应用中面临着数据标注成本高昂、耗时等挑战。
现在,我们介绍 Lightly Train,首个针对工业应用的 PyTorch 框架,它能让你在 无标签数据 上预训练计算机视觉模型,显著降低数据标注的依赖。
Lightly Train 的关键特性:
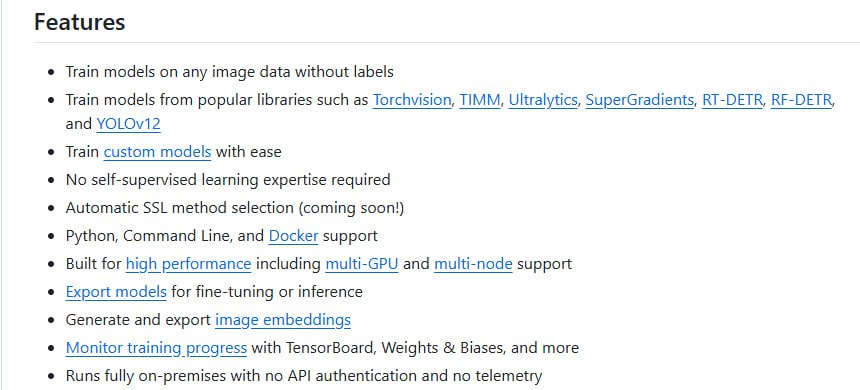
- 无需标签: 直接利用海量无标签图像和视频数据进行预训练,摆脱对昂贵标注数据的依赖。
- 工业级规模: 支持从数千到数百万张图像的工业级规模扩展,满足实际应用的需求。
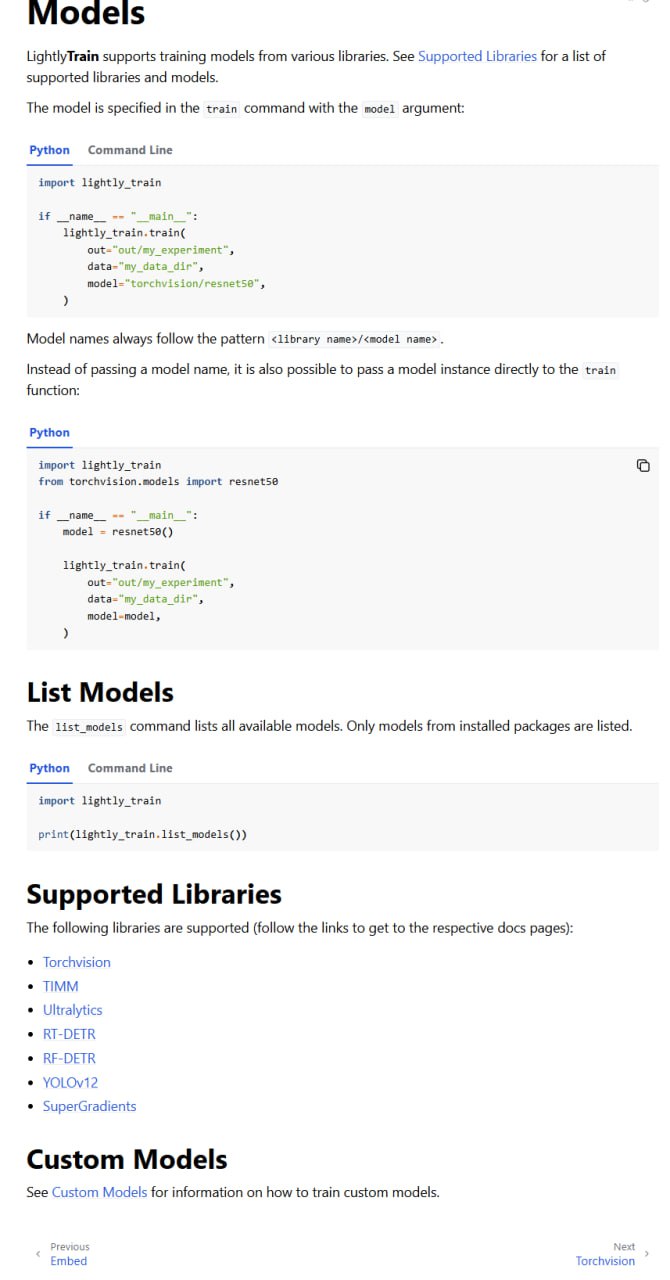
- 模型架构兼容: 兼容多种模型架构,包括 YOLOv8、ResNet 等,方便集成到现有系统中。
Lightly Train 提供了一个强大而灵活的平台,帮助企业和开发者利用海量未标记数据,构建高性能的计算机视觉模型,从而提高效率、降低成本。
更多信息请访问:lightly-train GitHub 仓库